Automation and centralisation of application monitoring – best practices
November 8, 2022 / 7 min read

Table of contents
- Automatization of application monitoring
- The benefits of automation in monitoring
- Web App Maintenance – common mistakes
- Automatization and centralisation of issues with Pagerduty – case study
- Key rules and best practises of automated application monitoring
- Why do you need centralized, automated web application monitoring?
For every business owner, struggles with downtimes and issues with their application can be a nightmare. Automatization and centralisation of application monitoring processes are the best remedy to these pains. By keeping the application functioning and acting before the tragedy, this approach leads to reducing costs of application support, minimising time spent on fixing issues and increasing the efficiency of the team.
With this approach we primarily aim to solve two core challenges of application monitoring:
- Decentralisation. Development and support teams use a lot of different tools and base their daily work on a complicated setup. This causes issues with maintaining and onboarding processes to multiple solutions. Centralisation leveraging most of the tools for monitoring processes handle the core functionalities needed to log, alert and notify – all in one place.
- Lack of automation. In modern times, innovative teams should aim for automation in order to limit manual, mundane and error-prone work. Support teams should monitor systems automatically, according to the pre-set rules and alerts.
Automatization of application monitoring
In order to maintain a market-leading level of availability of the application, a dedicated, centralised and automated monitoring service is needed. This approach is all about configuring a setup that will automatically track the application to detect any undesired occurrences and store every information about the performance of the solution in one place. It is used to monitor and control application’s infrastructure in real-time to guard it against downtimes even before the occur and are noticed by the users.
This setup is especially critical when a microservice architecture is introduced. In this scenario, there’s a myriad of various platforms and different technology solutions constantly connecting and scaling their instances up and down. Hence, an automated monitoring system is a necessity to achieve this predictable reliability and smooth user experience the stakeholders expect.
The benefits of automation in monitoring
This approach brings plenty of benefits to the table. There's more to it than simply saving time and money:
- Decreasing time of reaction to downtimes and errors
- Better error overview allowing to reveal patterns and thus stabilizing the IT ecosystem to proactively prevent further issues
- Eliminating the human element in monitoring, that the most prone to error
- Automating monitoring alerts basing on Key Performance Indicators
- Centralisation enabling easier access to logs, therefore improving investigation tools for developers
- Access to notifications from all services used in one place
- Increased possibility of handling demanding Service Level Agreements
- Boost in reliability and user experience of the application
Web App Maintenance – common mistakes
Looking at this long list of tangible benefits that directly impact the business result of the investment in the application, centralising and automating application monitoring processes should be a no-brainer.
Unfortunately, there’s still plenty of companies out there that continue to support and maintain the app manually - even though it’s nearly impossible to monitor the application 24/7 without suffering from issues falling through the cracks. There is plenty of common mistakes a development team can do when tenaciously sticking to manual monitoring.
This negligence often results from lack of clear strategy, budget constraints, simple inexperience, immature company culture, poor management or a typical short-sighted ‘we’ll fix it if its brakes’ approach.
That is why it is crucial to implement best practises of automatization and centralisation of application monitoring issues. How? Using proven in action tools such as Pagerduty, for example.
Automatization and centralisation of issues with Pagerduty – case study
At NoA Ignite, as we observed the issues with the process that was in place regarding one of the applications and listened to what our customers said about its flaws, we started working on an improved approach to monitoring.
We started with identifying the key challenges and expectations we had towards the new solution.
Our main goals were:
- automize the process of application monitoring as much as possible
- limit manual work wherever we can to minimize the risks of human error
- monitor the application and identify the issues before they occur
- minimize the number of tools used by the team
- simplify the process for customer benefit (financial and non-pecuniary)
- If possible, to find a solution for automized on-call support
With this in mind, we have conducted a thorough research.
Our aim was to find a tool which could help us meet all of goals we initially identified as the most important to the success of this project. We were looking for a solution that could allow us to integrate it with different tools we used at that time, and ideally, work well together with additional tools and systems we were planning to adopt in the future, as the project grows.
Since we were looking ideally at a long-lasting support in the upcoming years and were keen on not changing the support partner anytime soon, we decided to exclude niche solutions and inexperienced providers, we excluded niche solutions and prioritised offers with a possibly long-lasting support. During our research, we have selected 5 leading tools and compared key features.
The solution - Pagerduty
As a result, we identified that Pagerduty met our centralisation and automatization criteria.
| Pros of Pagerduty | Cons of Pagerduty |
|---|---|
| Automatic incidents created based on data feed from logging tools
Multiple integrations with most of the tools on the market Possible automation of processes (notification, escalation, incidents management) Automatic resource scheduling (on-call support) Centralized platform for incidents gathering Well established solution with a lot of customer cases |
High costs associated with number of users and business tiers
Advanced interface suited mostly for technical people |
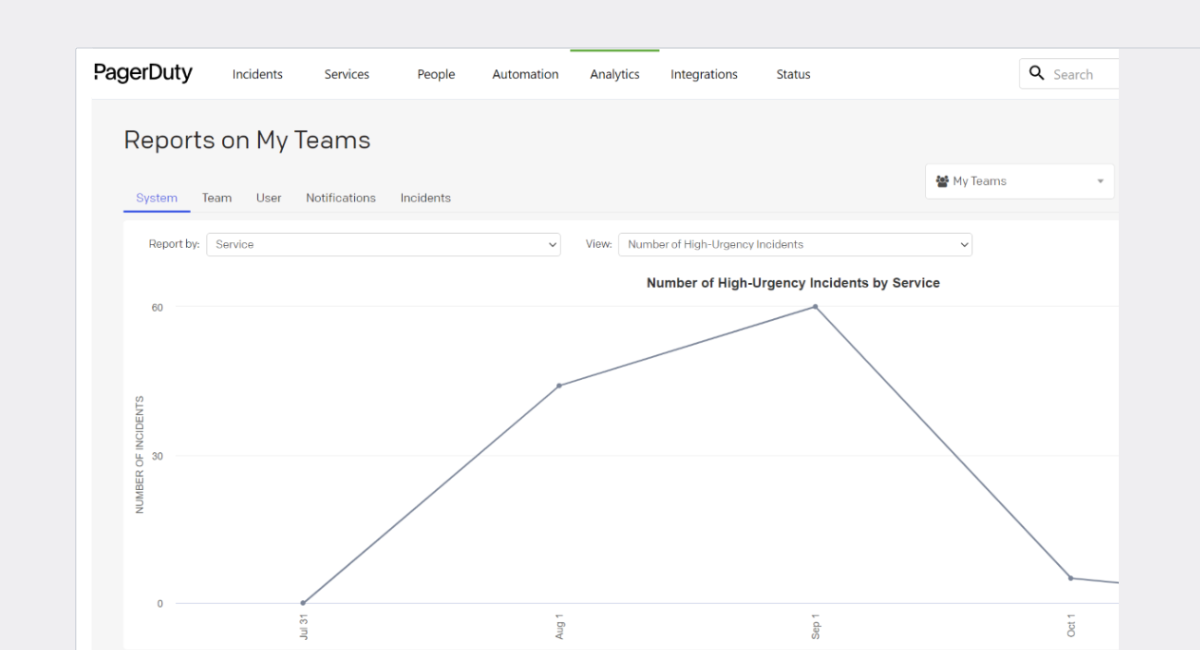
Our approach
We decided to service the most of our customer’s needs in one, general enterprise setup. For that sake, we separated three main SLA support streams:
- Automatic, based on Sentry alerts
- SLA ticketing via Zendesk
- on-call support via phone line
Fist SLA – Automatic setup leveraging Sentry
The main monitoring automation is handled via integration with Sentry. In this tool, we have configured alerts with thresholds associated with SLA levels - low, medium and critical. Basing on our investigation and experience we identified that for to meet SLA goals, the following factors should be measured:
- HTTP based errors
- Crash free sessions
- Number of failed events on the website
- Duration of events (response time of action on the website)
- Number of users experiencing errors in a 24h window
- Overall number of errors in a 24h window
- Any new type of errors created since last release
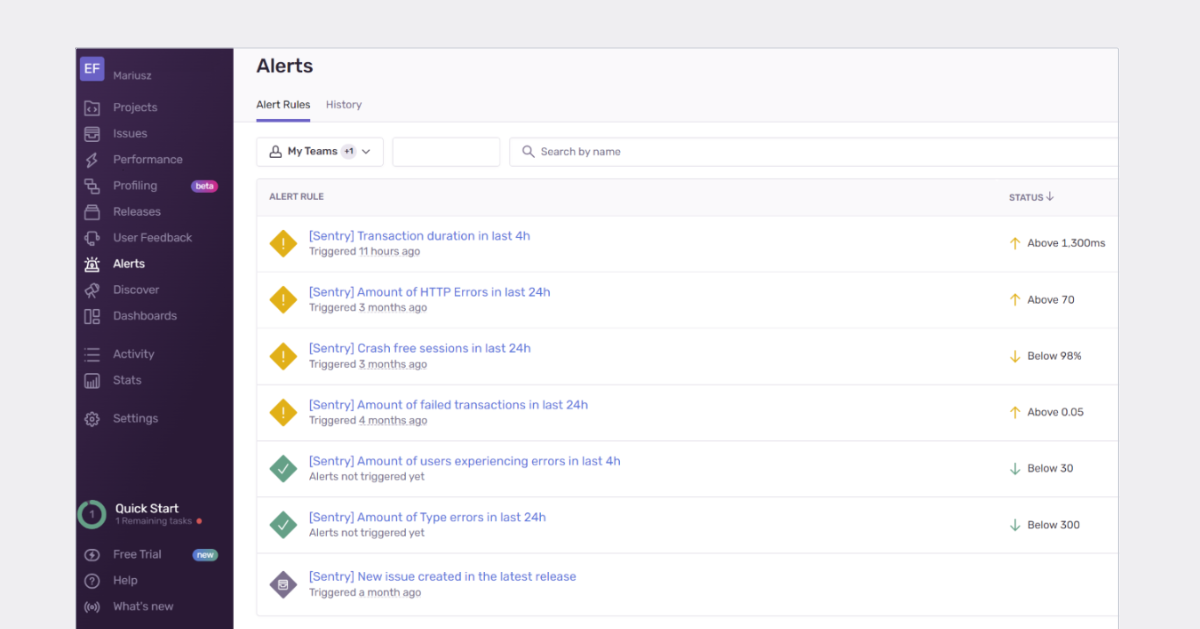
In case of exceeding the expected ‘normal’ threshold, a Pagerduty incident is created automatically. When the system identifies a ‘critical’ threshold is exceeded, a critical incident is created. We worked out these threshold levels empirically, by testing and observing. SLA incident levels in Pagerduty are also associated with different notification and escalation rules.
Here is how a sample automation scheme can look like:
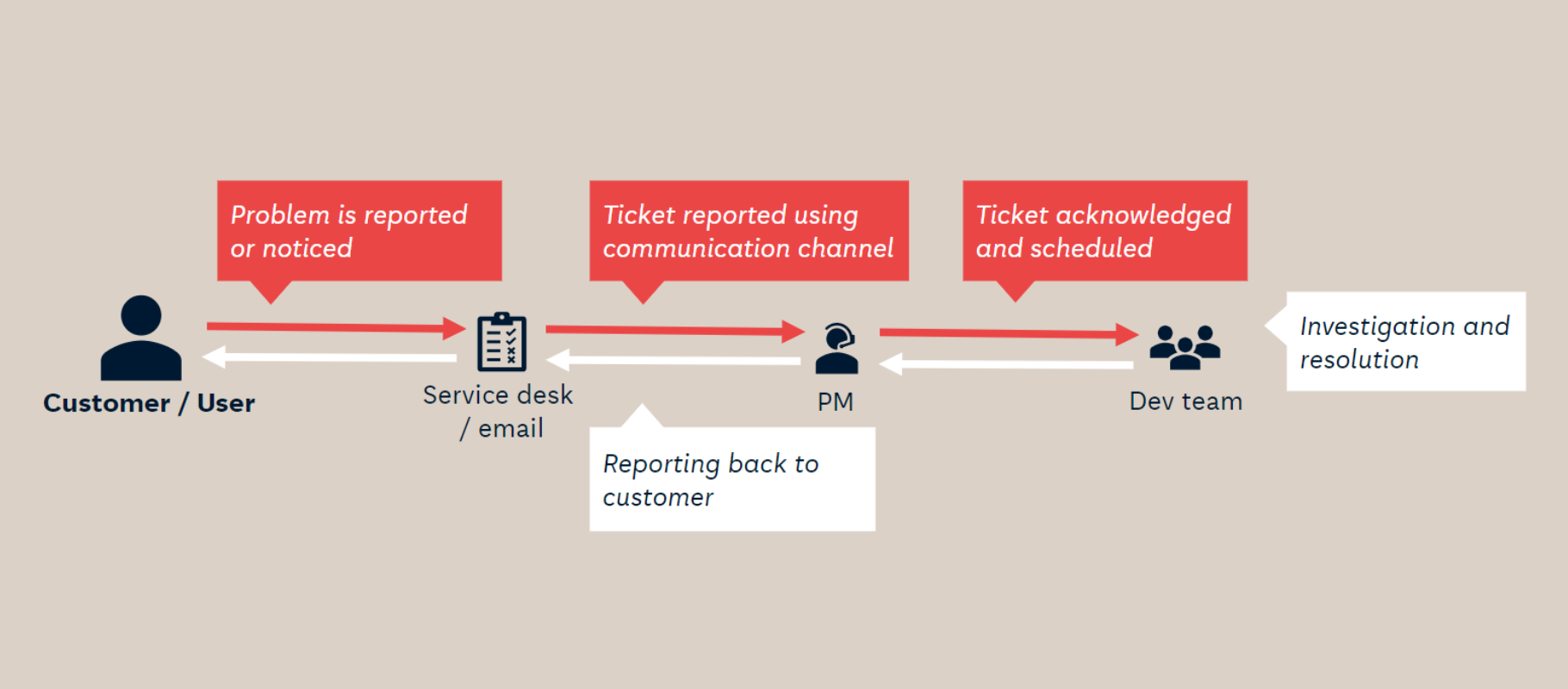
Second SLA – integration with Zendesk, a ticketing system
It was important to our customer to report observed issues, bugs, feedback from users and questions to our support. Our SLA agreements usually cover reaction time to any tickets - regardless of their level - and ticketing tools serve best for this purpose.
image source: https://support.zendesk.com/hc/en-us/community/posts/4409506839962-Views-Best-Practice
Most important pros of an automated ticketing solution are:
- High availability of the system for anyone at the customer’s team
- Quick ticket creation
- Good communication platform with SLA support team
- Keeping the once ticketed subject within one thread
- Integration with main SLA monitoring stream
- Ease of automatic assignment of a responsible agent
Third SLA – on-call support over the phone
Even though the current trends on the web support market tend to focus on availability of highly technical and automized platforms, it is still often crucial to have a well-known and reliable source of contact to support team in the form of a support phone number.
The main reasons for maintaining an on-call support line are:
- High availability and reliability of mobile phones
- Can be used by people who don’t have access to internet/browser
- Availability outside standard working hours
- Can be used during the night-time
- Direct contact with a dedicated developer
Naturally, this type of service comes with a certain additional cost, but at the same time, it grants the customer the possibility to access an on-call support line in non-standard hours. This kind of service can also be delivered in a 24/7 support model, if needed.
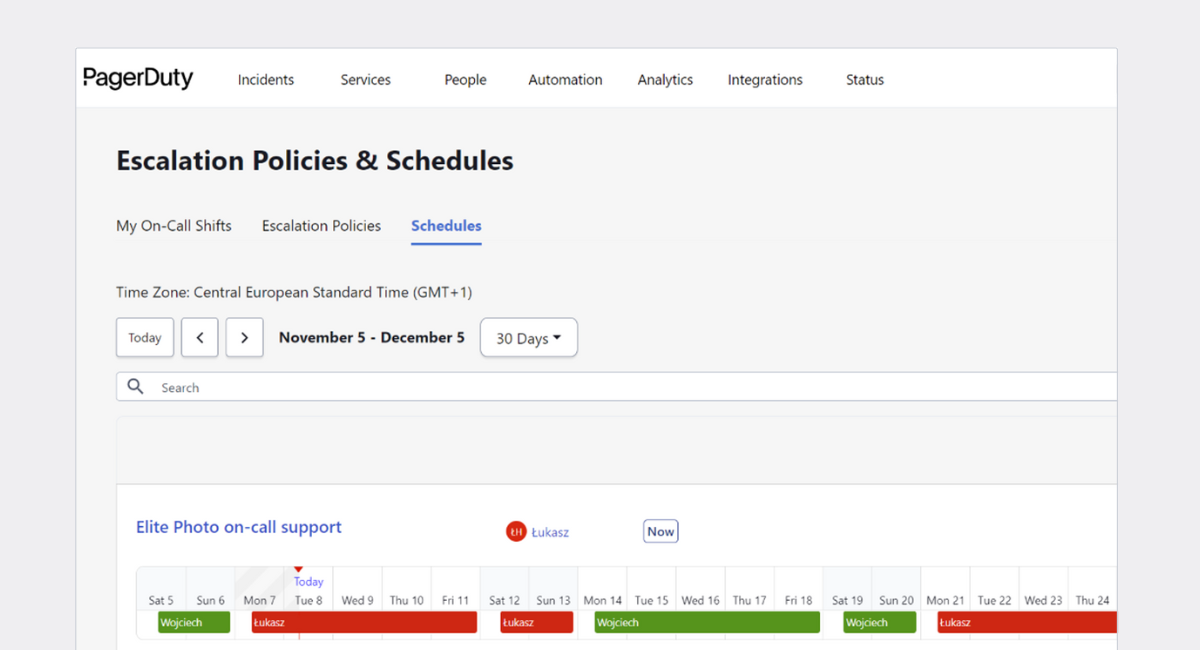
On-call support can also be automated. When a support line is called, Pagerduty automatically connects the calling customer with assigned developer, basing on an on-call schedule pre-set in Pagerduty. In case of no answer after predefined time (by default its 20 seconds), the call is redirected to a pre-set second escalation point.
Automated setup centralised in Pagerduty
The centralisation and automatization of our support streams based on Pagerduty allows us to gather incidents and manage automation, escalation, on-call support i__n one place__.
Key rules and best practises of automated application monitoring
When you try to adopt the setup of automation and centralisation, there is a list of best practises to follow, that will increase the chances of overall success of your initiatives:
Start as soon as possible
The sooner you start automating your processes and centralising them in one ecosystem, the better. Ideally, start from day 1. It takes some time to set everything up and to learn the ropes of automation.
Monitor everything
Infrastructure, architecture, user experience and any other component – monitor everything that has impact on the overall performance and market success of the application. This way you can stay on top of different kinds of risks in real-time.
Go for mature notification and reporting tooling
Focus on making notifications as clear and as useful as possible. Tools like Pagerduty are a great way to acknowledge issues, take the tickets and solve them. Reporting helps with understanding trends and identifying bottlenecks in a cohesive and transparent way.
Communicate and collaborate
Support and maintenance of an application can often be a teamwork. Using collaboration tools and communicating often – internally within the team and with the customer, will help you streamline the processes and strengthen the team spirit when facing frustrating and difficult issues.
Test to see what suits you best
With automation and centralisation there’s no one-size-fits-all solutions. Experiment, learn, improve and adapt constantly and iteratively, in a pre-set cadence. Try different tools, customise and integrate to make the most of them according to the current needs of the project.
Why do you need centralized, automated web application monitoring?
There can be only one summary to this article – automated and centralised application tooling is a necessity that sets you apart from the competitors and take the user experience of your application to the next level.
Monitoring the app and reporting identified issues can and should be done automatically and stored in a central repository, that leverages customisation and integrations with innovative solutions available on the market. The best practices and sample use case described in this article will help your support and maintenance team anticipate downtimes before they occur – all that to the increase the satisfaction of the users and the customer.
If you believe that you could benefit from that kind of setup, let us know! We’re happy to consult on your situation and explain how, basing on our experience, we could jointly take it up a notch.

Book a free consultation!
Downtimes and issues with your application give you sleepless nights? Talk to our experts to understand how to leverage automation to improve the bottom line!
Author

Mariusz Rajkowski
Project Manager
Mariusz is a Project Manager with several years of experience in project management in different areas of technology and business, as well as postgraduate studies in Project Management with a specialty in IT Project Management. Throughout his career, Mariusz has held the roles of advisor, platform specialist, and team leader, always offering professional support on both the consultative and project management levels.
Related articles
![A well-crafted prompt doesn’t just work once. It works across teams, channels, and campaigns. It can be tweaked for new use cases and refined based on what performs best.]()
June 27, 2025 / 4 min read
Prompts are marketing assets: how to reuse, and scale them
Prompts aren’t throwaway lines. They’re repeatable, scalable assets that can streamline your marketing your team’s output. Learn how to build a prompt library that delivers.
![Woman using a wheelchair in the office settings]()
June 17, 2025 / 5 min read
What is accessibility and why it matters?
Accessibility ensures everyone — including those with disabilities or limitations — can read, navigate, and engage with your content equally.

